Data Governance: The Hidden Vulnerability in Your AI Security Strategy
"Where is your source of truth for customer data, and who owns it?"

I keep having the same conversation with security leaders in the North American grocery retail space.
They're excited about deploying AI copilots. They want to embed LLMs into workflows, automate back office operations, and gain a competitive advantage. The enthusiasm is real.
Then I ask a simple question: "Where is your source of truth for customer data, and who owns it?"
Silence.
This isn't about one dramatic breach or headline moment. It's a pattern I've observed across dozens of conversations with large retailers. They're investing heavily in AI security tools—code scanners, prompt-injection protection, and vendor scorecards. All the visible, defensible layers.
But when I probe the fundamentals, the foundation crumbles.
The Promise Without Proof
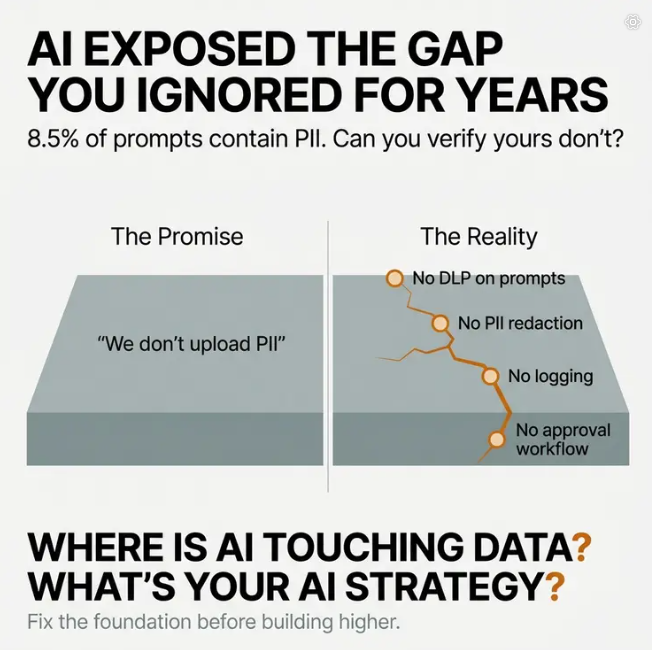
When that silence breaks, the answer usually comes with a hint of defensiveness: "We don't upload PII data into the LLMs."
That sounds reassuring. It functions as a policy statement, something you can tell the board or put in a compliance document.
But here's the problem: they can't actually verify it.
The gap between the promise and reality isn't malicious. It's structural. Most organizations lack four fundamental control mechanisms:
- DLP enforcement on prompts — Traditional data loss prevention systems weren't built for dynamic, unstructured AI prompts
- Automated PII redaction — No system actively strips sensitive data before it reaches the model
- Logging and inspection of prompt payloads — Prompts are treated as transient, passing through layers with minimal scrutiny
- Structured approval workflow for new use cases — Teams spin up AI tools without governance checkpoints
A recent study revealed that 8.5% of prompts submitted to tools like ChatGPT and Copilot included sensitive information—PII, credentials, internal file references. The vast majority weren't flagged by traditional systems because the exposure happened during natural language interactions, not during data entry or storage.
Your security posture has a blindspot. And AI just made it operationally visible.
Why Security Leaders Hesitate
When I point out these gaps, most security leaders don't dispute them. The friction isn't about recognition. It's about materiality and scope.
Two forces create paralysis:
Materiality: "Is this a board-level risk yet?" The answer feels ambiguous. AI adoption is accelerating—employee use tripled in one year, and data sent to these tools increased sixfold. But has it caused a breach? Not yet. So it stays in the "monitor" category.
Scope: "If this is real, it's much bigger than a tool." Once a security leader truly understands the problem, they realize fixing it requires organizational surgery:
- Cross-functional data stewardship
- Data classification cleanup
- Retention policy enforcement
- Logging redesign
- Possibly slowing AI rollout
Here's the uncomfortable truth: once they formally acknowledge the gap, they inherit responsibility for it.
That's where overwhelm creeps in. It's easier to stay in ambiguity than to own a problem this structural.
The Governance Programs That Failed
Most mid-to-large organizations already have data governance programs. On paper, they have data classification standards, retention schedules, access controls, named data owners, and annual compliance reviews.
So why didn't those programs catch these issues before AI exposed them?
Because those programs were built for a different threat model.
Traditional governance was designed for containment. It managed storage risk, access risk, and regulatory compliance. It assumed predictable data flow through well-defined systems.
AI collapses system boundaries. It recombines data across contexts, surfaces information through semantic retrieval, and operates at speeds that bypass human review loops.
Legacy governance managed where data sat. AI governance must manage how data moves, combines, and generates new outputs.
The gaps were always there. Unstructured data sprawl, unclear ownership, poor lineage tracking—these problems existed for years. AI didn't create them.
AI made them operationally visible and strategically consequential.
Before AI, poor governance caused inefficiency. After AI, poor governance creates amplified uncertainty.
Where to Start: Two Diagnostic Questions
When an organization recognizes this problem, I don't recommend full organizational surgery on day one. I ask two questions:
1. "Where is AI currently touching data, and what exactly is it touching?"
Most organizations can't map this accurately. They know AI tools are being used, but they lack visibility into which systems, which datasets, and which workflows are involved.
2. "What's your AI strategy?"
This isn't about vision statements. Knowing the fundamental reason why you're using AI reveals what you need to secure. AI governance isn't one-size-fits-all. It's use-case dependent.
The security model should follow the data exposure pattern created by the strategy.
A customer service copilot creates different exposure risks than an internal knowledge management tool. The former aggregates PII across customer interactions. The latter creates cross-silo inference risks with proprietary information.
Different exposure patterns require different control priorities.
A Framework for Rational Governance
You need a repeatable decision framework that ties:
Use Case → Data Exposure Pattern → Risk Category → Control Class → Implementation Priority
Skip the middle steps, and you either over-secure everything or secure nothing well.
Let me show you what this looks like in practice.
Real Example: Retail Support Copilot
A large grocery retailer deployed an AI copilot inside their ticketing system to help support agents respond faster to customer inquiries. Not a public chatbot—an internal assistant that suggests responses based on:
- Current ticket content
- Customer history
- Order history
- Return policy documentation
- Past similar tickets
The goal: reduce handle time, improve consistency, increase agent productivity.
Step 1: Map the Exposure Pattern
The AI ingests the active ticket, pulls semantically similar historical tickets, synthesizes a recommended response, and displays it to the agent.
The critical shift: the AI is recombining customer histories across tickets.
That recombination never happened at scale before. The exposure pattern is cross-ticket semantic aggregation of PII-rich unstructured data.
Step 2: Identify the Dominant Risk
Primary risks include:
- Disclosure risk — The AI could surface fragments from another customer's ticket
- Inference risk — It could recombine data in ways the agent wouldn't manually access
- Integrity risk — It could hallucinate policy exceptions
The dominant risk: cross-session disclosure of PII via retrieval errors.
Step 3: Translate Risk to Control Class
Because the dominant risk is disclosure via retrieval, the relevant control categories are:
- Session isolation
- Corpus segmentation
- Permission inheritance validation
- Output inspection
- Retrieval boundary controls
Not an enterprise AI firewall purchase. Not massive reclassification of the entire data estate. Targeted controls.
Step 4: Prioritize by Impact, Feasibility, and Evidence
Tier 1 (First 60 Days):
- Log all prompts and outputs
- Conduct 200-500 interaction sampling audit
- Validate retrieval respects existing ticket access controls
- Create exclusion list (VIP cases, escalations)
Result: You now know if bleed is happening.
Tier 2 (Quarter 2-3):
- Restrict retrieval to same customer ID
- Implement output scanning for foreign identifiers
- Add confidence thresholds for auto-send
- Create incident review loop for AI-generated errors
Now you're constraining behavior.
Tier 3 (Longer Horizon):
- Assign support data steward
- Clean legacy tickets
- Align retention policy
- Build AI governance reporting into risk committee
Now you're maturing the structure.
The "Oh Shit" Moment
When organizations implement those Tier 1 controls and run that initial prompt logging audit, they discover something uncomfortable.
The problem isn't theoretical. It's happening right now.
Prompts contain PII. Outputs surface data from unrelated customer accounts. Historical tickets with embedded sensitive information get pulled into new contexts. The "we don't upload PII" policy statement collides with operational reality.
That's when the conversation shifts from "should we prioritize this?" to "we need to deal with this right now."
Why This Matters Beyond Security
AI risk and compliance has matured from theoretical discussions to enforceable legal requirements with substantial penalties. The EU AI Act reaches general application in 2026. Colorado's AI regulations take effect. Regulators expect documented governance programs, not just policies.
Fines can reach up to 10% of global turnover in GDPR-style regimes.
But beyond regulatory pressure, there's a competitive dimension. Organizations with robust data governance can deploy AI faster, with more confidence, and with less risk exposure. Companies adopting automation report up to 60% reduction in audit preparation time and 70% higher accuracy in lineage documentation.
Data governance transforms from a security requirement into a business differentiator.
The Framework Forces Discipline
Without a structured approach, organizations jump straight to "let's buy an AI security product."
With this framework, governance becomes rational:
- Start with the strategy
- Map how data moves differently
- Identify the dominant risk
- Translate that into a control category
- Sequence by evidence and feasibility
You're not securing "AI." You're securing the new information flow your strategy created.
The gaps in your data governance were always there. AI just made them impossible to ignore.
The question isn't whether to address them. It's whether you'll do it proactively or reactively.
I recommend proactive.



